کلان داده
این مطلب در حال تکمیل است. شما نیز میتوانید در تکمیل آن مشارکت داشته باشید
عبارت Big Data مدتها است که برای اشاره به حجمهاي عظیمی از دادهها که توسط سازمانهای بزرگی مانند گوگل یا ناسا ذخیره و تحلیل ميشوند مورد استفاده قرار ميگیرد. اما به تازگي، این عبارت بیشتر برای اشاره به مجموعههای دادهاي بزرگی استفاده ميشود که به قدری بزرگ و حجیم هستند که با ابزارهای مدیریتی و پایگاههاي داده سنتي و معمولي قابل مدیریت نیستند. مشکلات اصلي در کار با این نوع دادهها مربوط به برداشت و جمعآوری، ذخیرهسازی، جستوجو، اشتراکگذاری، تحلیل و نمایش آنها است. این مبحث، به این دلیل هر روز جذابیت و مقبولیت بیشتری پیدا ميکند که با استفاده از تحلیل حجمهاي بیشتری از دادهها، ميتوان تحلیلهاي بهتر و پيشرفتهتري را برای مقاصد مختلف، از جمله مقاصد تجاری، پزشکی و امنیتی، انجام داد و نتایج مناسبتری را دریافتکرد. بيشتر تحلیلهای مورد نیاز در پردازش دادههاي عظیم، توسط دانشمندان در علومی مانند هواشناسی، ژنتیک، شبیهسازیهاي پیچیده فیزیک، تحقیقات زیستشناسی و محیطی، جستوجوی اینترنت، تحلیلهاي اقتصادی و مالی و تجاری مورد استفاده قرار ميگیرد. حجم دادههاي ذخیرهشده در مجموعههاي دادهاي Big Data، عموماً بهخاطر تولید و جمعآوری دادهها از مجموعه بزرگی از تجهیزات و ابزارهای مختلف مانند گوشیهاي موبایل، حسگرهای محیطی، لاگ نرمافزارهای مختلف، دوربینها، میکروفونها، دستگاههاي تشخیص RFID، شبکههاي حسگر بیسیم وغيره با سرعت خیرهکنندهاي در حال افزایش است. در این مقاله ضمن بررسی مفاهیم پایه ای در بزرگ داده، به بررسی راه حل های موجود برای مدیریت و بهره برداری از این نوع داده ها خواهیم پرداخت.
معادل فارسی
معادل های پیشنهادی برای Big Data:
- داده های انبوه: انبوه بیشتر اشاره به واژه هایی نظیر dense و mass دارد و بعنوان معادل برای big مناسب بنظر نمیرسد
- داده های حجیم: این عنوان بنظر مناسب نیست، زیرا بیشتر به بعد Volume یا حجم که یکی از چالش های حوزه Big data است اشاره میکند.
- داده های عظیم: این عنوان بدلیل اینکه ریشه عربی دارد پیشنهاد نمیشود. ضمن اینکه بیشتر معادل کلماتی نظیر great، huge و enormous می باشد.
- بزرگ داده: این واژه در حال حاضر بیشتر برای معادل کلمه Large استفاده میشود (نظیر Large Scale : مقیاس بزرگ) و بنابراین پیشنهاد نمیشود.
- وزرگ داده: این عنوان همان بزرگ است که در فارسی قدیم برای اشاره به عظمت مقام و یا وسعت قلمرو (معادل great و vast) استفاده شده است.
- کلان داده: این عنوان به نظر میرسد که برای Big Data مناسبتر باشد. زیرا ترکیبات مشابه دیگری نیز دارد که ترجمه کلان برای آنها نیز استفاده میشود (نظیر Big Approach : رویکرد کلان)
مثال کاربردی
برای ایجاد یک دید مناسب در خصوص کلان داده و اهمیت آن، جامعه ای را تصور کنید که در آن جمعیت بطور نمایی در حال افزایش است، اما خدمات و زیرساخت های عمومی آن نتواند پاسخگوی رشد جمعیت باشد و از عهده مدیریت آن برآید. چنین شرایطی در حوزه داده در حال وقوع است. بنابراین نیازمند توسعه زیرساخت های فنی برای مدیریت داده و رشد آن در بخش هایی نظیر جمع آوری، ذخیره سازی، جستجو، به اشتراک گذاری و تحلیل می باشیم. دستیابی به این توانمندی معادل است با شرایطی که مثلا بتوانیم "هنگامی که با اطلاعات بیشتری در حوزه سلامت مواجه باشیم، با بازدهی بیشتری سلامت را ارتقا دهیم"، "در شرایطی که خطرات امنیتی افزایش پیدا میکند، سطح امنیت بیشتری را فراهم کنیم"، "وقتی که با رویدادهای بیشتری از نظر آب و هوایی مواجه باشیم، توان پیش بینی دقیقتر و بهتری بدست آوریم"، "در دنیایی با خودروهای بیشتر، آمار تصادفات و حوادث را کاهش دهیم"، "تعداد تراکنش های بانکی، بیمه و مالی افزایش پیدا کند، ولی تقلب کمتری را شاهد باشیم"، "با منابع طبیعی کمتر، به انرژی بیشتر و ارزانتری دسترسی داشته باشیم" و بسیاری موارد دیگر از این قبیل که اهمیت پنهان کلان داده را نشان می دهد.
چالش های حوزه کلان داده
در بحث کلان داده، ما نیاز داریم که داده ها را به منظور استخراج اطلاعات، کشف دانش و در نهایت تصمیم گیری در خصوص مسائل مختلف کاربردی به صورت صحیح مدیریت کنیم. مدیریت داده ها عموما شامل 5 فعالیت اصلی میباشد.
- جمع آوری
- ذخیره سازی
- جستجو
- به اشتراک گذاری
- تحلیل
تا کنون چالشهای زیادی در حوزه کلان داده مطرح شده است که تا حدودی از جنبه تئوری ابعاد مختلفی از مشکلات این حوزه را بیان میکنند. این چالش ها در ابتدا سه بعد اصلی حجم داده، نرخ تولید و تنوع به عنوان 3V’s مطرح شدند ولی در ادامه چالش های بیشتری در ادبیات موضوع توسط محققان مطرح شده است:
- حجم داده (Volume): حجم داده ها به صورت نمایی در حال رشد می باشد. منابع مختلفی نظیر شبکه های اجتماعی، لاگ سرورهای وب، جریان های ترافیک، تصاویر ماهواره ای، جریان های صوتی، تراکنش های بانکی، محتوای صفحات وب، اسناد دولتی و ... وجود دارد که حجم داده بسیار زیادی تولید می کنند.
- نرخ تولید (Velocity): داده ها از طریق برنامه های کاربردی و سنسورهای بسیار زیادی که در محیط وجود دارند با سرعت بسیار زیاد و به صورت بلادرنگ تولید می شوند. بسیاری از کاربردها نیاز دارند به محض ورود داده به درخواست کاربر پاسخ دهند. ممکن است در برخی موارد نتوانیم به اندازه کافی صبر کنیم تا مثلا یک گزارش در سیستم برای مدت طولانی پردازش شود.
- تنوع (Variety): انواع منابع داده و تنوع در نوع داده بسیار زیاد می باشد که در نتیجه ساختارهای داده ای بسیار زیادی وجود دارد. مثلا در وب، افراد از نرم افزارها و مرورگرهای مختلفی برای ارسال اطلاعات استفاده می کنند. بسیاری از اطلاعات مستقیما از انسان دریافت میشود و بنابراین وجود خطا اجتناب ناپذیر است. این تنوع سبب میشود جامعیت داده تحت تاثیر قرار بگیرد. زیرا هرچه تنوع بیشتری وجود داشته باشد، احتمال بروز خطای بیشتری نیز وجود خواهد داشت.
- صحت (Veracity): با توجه به اینکه داده ها از منابع مختلف دریافت میشوند، ممکن است نتوان به همه آنها اعتماد کرد. مثلا در یک شبکه اجتماعی، ممکن است نظرهای زیادی در خصوص یک موضوع خاص ارائه شود. اما اینکه آیا همه آنها صحیح و قابل اطمینان هستند، موضوعی است که نمیتوان به سادگی از کنار آن در حجم بسیار زیادی از اطلاعات گذشت. البته بعضی از تحقیقات این چالش را به معنای حفظ همه مشخصه های داده اصلی بیان کرده اند که باید حفظ شود تا بتوان کیفیت و صحت داده را تضمین کرد. البته تعریف دوم در مولدهای کلان داده صدق میکند تا بتوان داده ای تولید کرد که نشان دهنده ویژگی های داده اصلی باشد.
- اعتبار (Validity): با فرض اینکه دیتا صحیح باشد، ممکن است برای برخی کاربردها مناسب نباشد یا به عبارت دیگر از اعتبار کافی برای استفاده در برخی از کاربردها برخوردار نباشد.
- نوسان (Volatility): سرعت تغییر ارزش داده های مختلف در طول زمان میتواند متفاوت باشد. در یک سیستم معمولی تجارت الکترونیک، سرعت نوسان داده ها زیاد نیست و ممکن است داده های موجود مثلا برای یک سال ارزش خود را حفظ کنند، اما در کاربردهایی نظیر تحلیل ارز و بورس، داده با نوسان زیادی مواجه هستند و داده ها به سرعت ارزش خود را از دست میدهند و مقادیر جدیدی به خود می گیرند. اگرچه نگهداری اطلاعات در زمان طولانی به منظور تحلیل تغییرات و نوسان داده ها حائز اهمیت است. افزایش دوره نگهداری اطلاعات، مسلما هزینه های پیاده سازی زیادی را دربر خواهد داشت که باید در نظر گرفته شود.
- نمایش (Visualization): یکی از کارهای مشکل در حوزه کلان داده، نمایش اطلاعات است. اینکه بخواهیم کاری کنیم که حجم عظیم اطلاعات با ارتباطات پیچیده، به خوبی قابل فهم و قابل مطالعه باشد از طریق روش های تحلیلی و بصری سازی مناسب اطلاعات امکان پذیری است.
- ارزش (Value): این موضوع دلالت بر این دارد که از نظر اطلاعاتی برای تصمیم گیری چقدر داده حائز ارزش است. بعبارت دیگر آیا هزینه ای که برای نگهداری داده و پردازش آنها میشود، ارزش آن را از نظر تصمیم گیری دارد یا نه. معمولا داده ها میتوانند در لایه های مختلف جابجا شوند. لایه های بالاتر به معنای ارزش بیشتر داده می باشند. بنابراین برخی از سازمانها میتوانند هزینه بالای نگهداری مربوط به لایه های بالاتر را قبول کنند.
دسته بندی ها
در تصاویر زیر انواع دسته بندی های انجام شده در حوزه کلان داده نشان داده شده است.
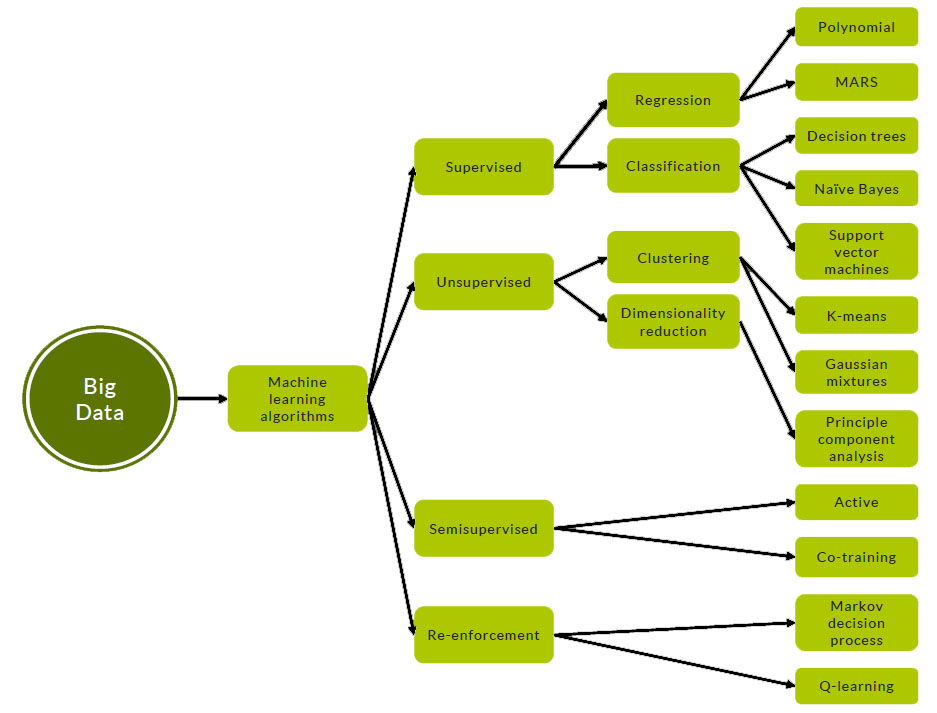
الگوریتم های یادگیری ماشین در حوزه کلان داده
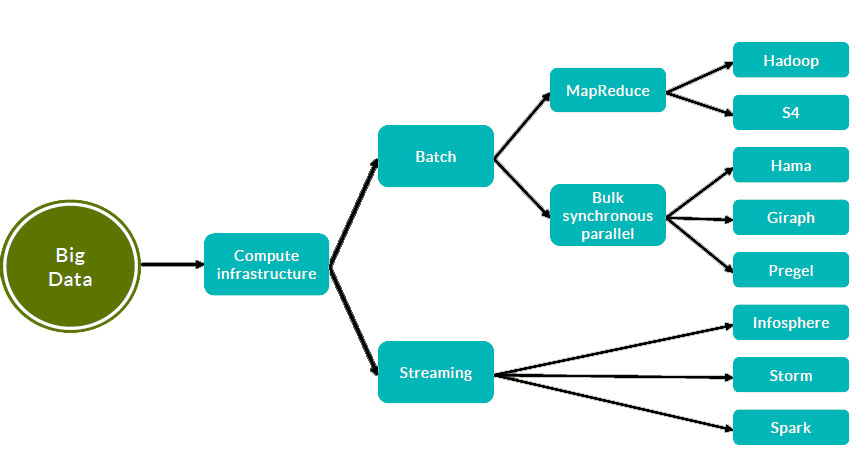
زیرساخت های محاسباتی کلان داده
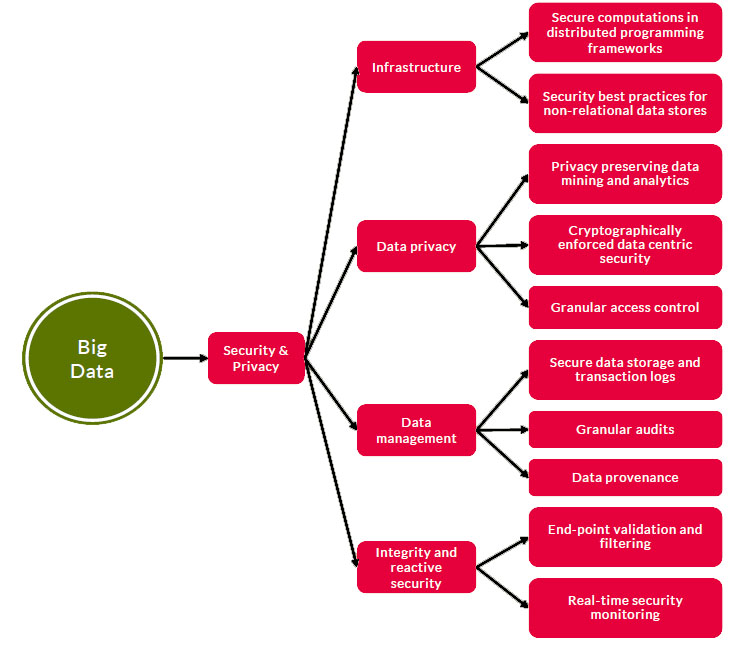
ابعاد امنیتی کلان داده
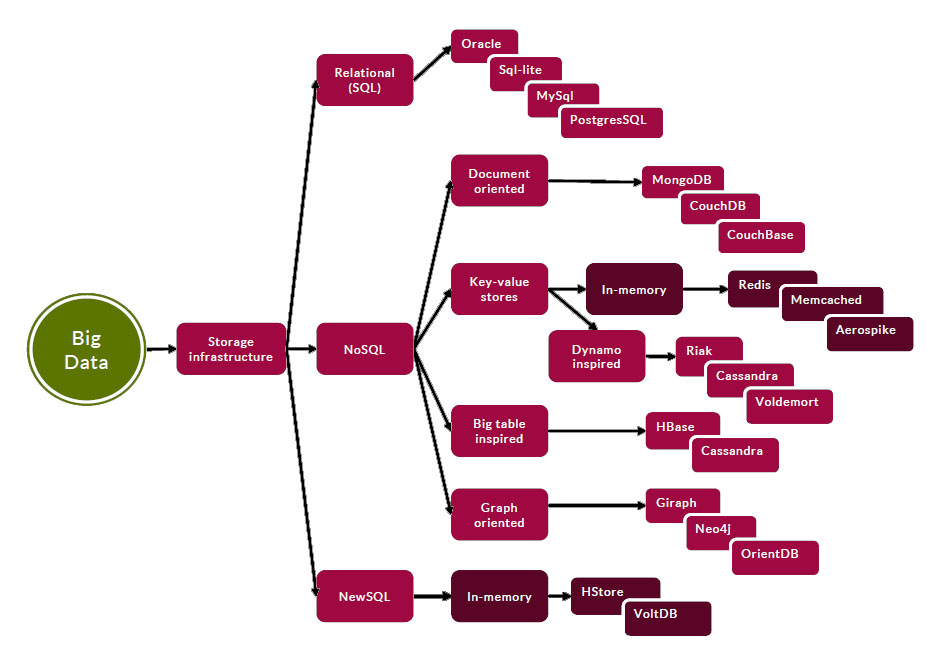
زیرساخت ها و فناوری های ذخیره سازی کلان داده
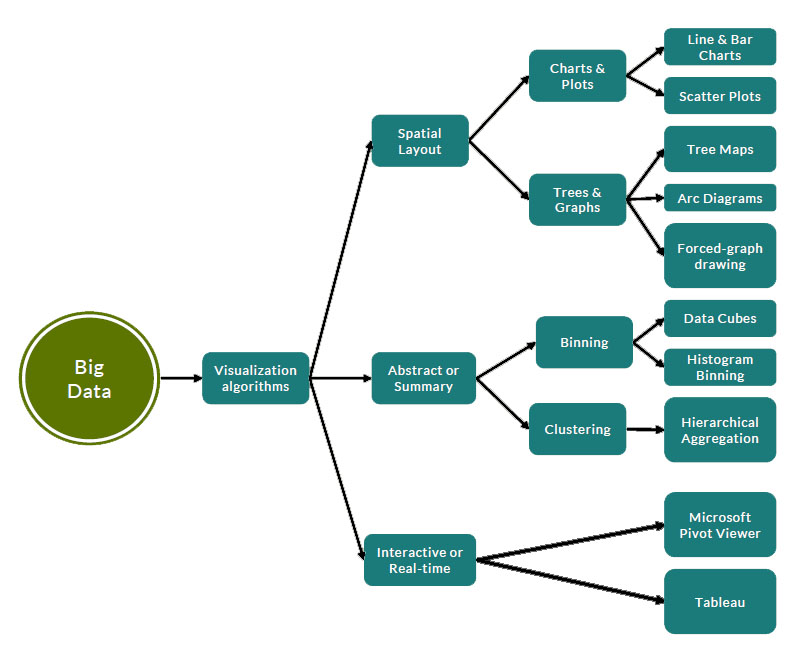
الگوریتم های مصورسازی کلان داده





ابزارها و فناوری ها
ابزارها و فناوری های مرتبط به این شرح می باشد:
- مجازی سازی داده
- SmartData
- Hadoop
- NoSQL
- Graph DB
- MapGraph
- Owncloud
- Swift
- Dropbox
- Box.net
- Google Drive
- Amazon S3
- MapReduce
- Cloud Dataflow
- Trove
- Sahara
- Clustrix
- SQL
- MySQL
- Postgress
- Memcache
- Riak
- HBase
- Cassandra
- Python
- Oracle
- DB2
- Vert.x
- OpenShift
- Pig
- MongoDB
- Apache Spark
- Apache Nutch
- MongoDB
- Redis
اگر ابزار یا فناوری دیگری بنظر شما وجود دارد به این لیست اضافه کنید یا برای موارد موجود شرح بیشتری در صفحه مربوط به آنها اضافه نمایید.
کدام پایگاه داده NoSQL بهتر است؟
معیارهای زیادی برای انتخاب یک پایگاه داده NoSQL وجود دارد. از جمله موارد مهم در انتخاب پایگاه داده مناسب در نظر گرفتن تئوری CAP متناسب با کاربرد و نیازمندی های آن است. همچنین این سایت میتواند دید مناسبی در خصوص پارامترهای مختلف به شما بدهد.
لینک های مرتبط
- کلان داده
- مجازی سازی داده
- کارگروه BigData
- بورد مربوط به فعالیت های کارگروه کلان داده
- برنامه ریزی در حوزه کلان داده
- بررسی چالش واقعی سازمانها در رابطه با کلان داده ها و بررسی دقیقتر مدلهای کلان داده
- پیاده سازی سیستم های اطلاعاتی با حجم دیتای بالا و پراکندگی جغرافیایی بر بستر ابر
- ارائه راهکارهایی جهت رفع مشکل پراکندگی جغرافیایی
- تحلیلی در خصوص وضعیت ذخیره سازی در سال 2014
- Big_Data_Taxonomy.pdf