مجموعه داده های مرتبط با رایانش ابری
در این صفحه دوستان میتوانند مجموعه داده های مرتبط با رایانش ابری را جهت استفاده های تحقیقاتی به اشتراک بگذارند. همچنین مجموعه کارهایی که بصورت خاص در زمینه مدیریت منابع (نظیر زمان بندی منابع) بر اساس مجموعه داده های موجود انجام شده است نیز ارایه شده است که میتوانید در تکمیل آن نیز مشارکت داشته باشید.
The San Diego Supercomputer Center (SDSC) Blue Horizon log
این مجموعه داده متعلق به مرکز ابررایانه San Diego [۱] است. این مجموعه داده در پژوهش های متعددی در حوزه رایانش ابری مورد استفاده قرار گرفته است.
دانلود مجموعه داده
- دانلود نسخه اصلی مجموعه داده (6.0 مگابایت): SDSC-BLUE-2000-0.gz
- دانلود نسخه تبدیل شده مجموعه داده (3.9 مگابایت): SDSC-BLUE-2000-4.swf.gz
- دانلود نسخه تبدیل شده و تمیز شده مجموعه داده (3.8 مگابایت): SDSC-BLUE-2000-4.1-cln.swf.gz
مشخصلات لاگ
System: 144-node IBM SP, with 8 processors per node
Duration: Apr 2000 thru Jan 2003
Jobs: 250,440
Description: An extensive log, starting when the machine was just installed, and then covering more than two years of production use.
It contains information on the requested and used nodes and time, CPU time, submit, wait and run times, and user.
The workload log from the SDSC Blue Horizon was graciously provided by Travis Earheart and Nancy Wilkins-Diehr,
who also helped with background information and interpretation.
If you use this log in your work, please use a similar acknowledgment.
محیط سیستم
The total machine size is 144 nodes. Each is an 8-way SMP with a crossbar connecting the processors to a shared memory. These nodes are for batch use, with jobs submitted using LoadLeveler. The data available here comes from LoadLeveler. The log also contains interactive jobs up to July 2002. At about that time an additional 15 nodes were acquired for interactive use, e.g. development. These nodes have only ethernet communication, employ timesharing scheduling, and reportedly have only 4 processors each. These nodes are handled by a separate instance of LoadLeveler, and their workload is not available here. The scheduler used on the machine is called Catalina. This was developed at SDSC, and is similar to other batch schedulers. It uses a priority queue, performs backfilling, and supports reservations.
Jobs are submitted to a set of queues. The main ones are
| Name | Time limit | Node limit |
| interactive | 2hr | 8 |
| express | 2hr | 8 |
| high | 36hr | -- |
| normal | 36hr | -- |
| low | -- | -- |
According to on-line documentation, towards the end of 2001 the limits were different:
| Name | Time limit | Node limit |
| interactive | 2hr | -- |
| express | 2hr | 8 |
| high | 18hr | 31 |
| normal | 18hr | 31 |
| low | 18hr | 31 |
فرمت مجموعه داده
The original log is available as SDSC-BLUE-2000-0. This was originally provided as three separate yearly files, which have been concatanated to produce this file. The data contains one line per job with the following white-space separated fields:
- User (sanitized as User1, User2, ...)
- Queue (interactive, express, high, normal, low, unknown)
- Total CPU time
- Wallclock time
- Service units (used in accounting)
- Nodes used
- Maximal nodes used
- Number of jobs run (always 1)
- Max memory (unused)
- Memory (unused)
- I/O (unused)
- Disk space (unused)
- Connect time (unused)
- Waiting time
- Slowdown
- Priority (maps to queue)
- Submit date and time
- Start date and time
- End date and time
- Requested wallclock time
- Requested memory (unused)
- Requested nodes
- Completion status
اطلاعات تبدیل
The converted log is available as SDSC-BLUE-2000-4.swf. The conversion from the original format to SWF was done subject to the following.
* The original log specifies the number of nodes each job requested and received. In the conversion this was multiplied by 8 to get the number of processors.
* The original log contains dates and times in human-readable format, e.g. 2000-12-28--22:58:35.
However, the submit times create a daily cycle which peaks at night (see graph below),
probably due to inconsistent use of the gmtime and localtime functions when the data was collected.
Therefore the default San Diego time-zone shift of 8 hours was postulated.
This was implemented by using timegm rather than timelocal to produce a UTC timestamp.
* The original log contains some fields that can be used for sanity checks, but seem to be unreliable.
For example, the wallclock field is often less than the difference between the start and end times, and also the CPU time.
The wait time field also does not necessarily match the difference between the start and submit times. These discrepancies were ignored.
* The conversion loses the following data, that cannot be represented in the SWF:
* The maximal number of nodes used. In 184 jobs this was lower than the number of nodes allocated.
* The priority and service unites. Note that the priority is not a job-specific priority but rather the priority of the queue to which it was submitted.
The service units charged are the product of wallclock time and priority (times 8).
* The following anomalies were identified in the conversion:
* 458 jobs got more processors than they requested. In some (but not all) cases this seems to be rounding up to a power of 2.
* 253 jobs got less processors than they requested.
* 23,491 jobs got more runtime than they requested. In 8,167 cases the extra runtime was larger than 1 minute.
* 12140 jobs with "failed" status had undefined start times. In 262 of them the start time and run time were approximated using CPU time.
* 25,735 jobs were recorded as using 0 CPU time; this was changed to -1. 4203 of them had "success" status.
* 15 jobs had an average CPU time higher than their runtime. In 2 cases the extra CPU time was larger than 1 minute.
* 20,773 jobs were recorded as using 0 processors, of which 20771 had a status of "cancelled". This was changed to -1
* 792 jobs enjoyed a negative wait time (start time was before submit time), and for 28 the difference was more than 1 minute.
It is assumed that this is the result of unsynchronized clocks. These wait times were changed to 0, effectively shifting the start (and end) times.
* in 2 jobs the status was missing.
شرح استفاده
The original log contains several flurries of very high activity by individual users, which may not be representative of normal usage.
These were removed in the cleaned version, and it is recommended that this version be used.
The cleaned log is available as SDSC-BLUE-2000-4.1-cln.swf.
A flurry is a burst of very high activity by a single user. The filters used to remove the three flurries that were identified are
* user=68 and job>57 and job<565 (477 jobs)
* user=342 and job>88201 and job<91149 (1468 jobs)
* user=269 and job>200424 and job<217011 (5181 jobs)
Note that the filters were applied to the original log, and unfiltered jobs remain untouched. As a result, in the filtered logs job numbering is not consecutive.
Further information on flurries and the justification for removing them can be found in:
* D. G. Feitelson and D. Tsafrir, ``Workload sanitation for performance evaluation.
In IEEE Intl. Symp. Performance Analysis of Systems and Software, pp. 221-230, Mar 2006.
* D. Tsafrir and D. G. Feitelson, ``Instability in parallel job scheduling simulation: the role of workload flurries.
In 20th Intl. Parallel and Distributed Processing Symp., Apr 2006.
تصاویر مربوط به مجموعه داده
در این قسمت تصاویر مربوط به مجموعه داده را مشاهده مینمایید.
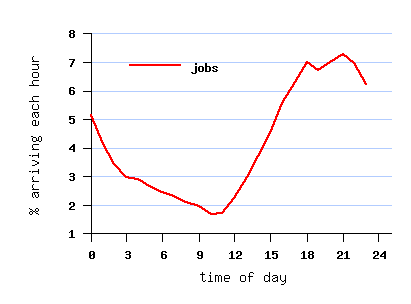
مربوط به مجموعه داده File SDSC-BLUE-2000-0 قبل از تبدیل
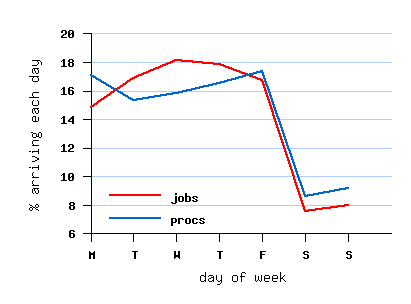
مربوط به مجموعه داده تبدیل یافته File SDSC-BLUE-2000-4.swf
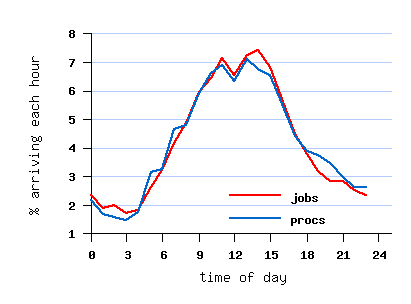
مربوط به مجموعه داده تبدیل یافته File SDSC-BLUE-2000-4.swf
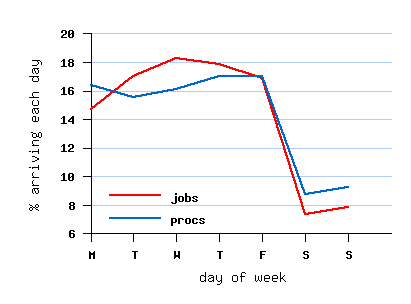
مربوط به مجموعه داده تبدیل یافته و تمیز شده File SDSC-BLUE-2000-4.1-cln.swf
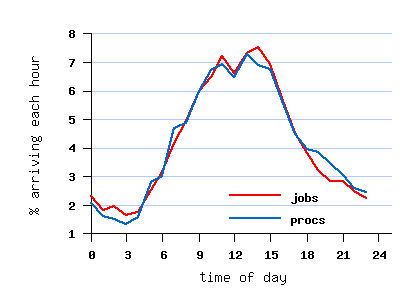
مربوط به مجموعه داده تبدیل یافته و تمیز شده File SDSC-BLUE-2000-4.1-cln.swf





مراجع
در منابع زیر از این مجموعه داده استفاده شده است:
[agmonby11] Orna Agmon Ben-Yehuda, Muli Ben-Yehuda, Assaf Schuster, and Dan Tsafrir, “Deconstructing Amazon EC2 Spot Instance Pricing”. In 3rd Intl. Conf. Cloud Computing Tech. & Sci., pp. 304--311, Nov 2011.
[aida09] Kento Aida and Henri Casanova, “Scheduling Mixed-Parallel Applications with Advance Reservations”. Cluster Comput. 12(2), pp. 205--220, Jun 2009.
[amar08a] Lior Amar, Ahuva Mu'alem, and Jochen Stößer, “On the Importance of Migration for Fairness in Online Grid Markets”. In 9th IEEE Grid Comput. Conf., pp. 65--74, Sep 2008.
[amar08b] Lior Amar, Ahuva Mu'alem, and Jochen Stößer, “The Power of Preemption in Economic Online Markets”. In 5th Grid Economics and Business Models, Springer-Verlag, Lect. Notes Comput. Sci. vol. 5206, pp. 41--57, 2008. Annotation: Preemption improves both theoretical bounds and empirical simulations of scheduling in a non-cooperative setting.
[bacso14] Gábor Bacsó, Ádám Visegrádi, Attila Kertesz, and Zsolt Németh, “On Efficiency of Multi-Job Grid Allocation Based on Statistical Trace Data”. J. Grid Comput. , 2014.
[buyya09] Rajkumar Buyya, Chee Shin Yeo, Srikumar Venugopal, James Broberg, and Ivona Brandic, “Cloud computing and emerging IT platforms: Vision, hype, and reality for delivering computing as the 5th utility”. Future Generation Comput. Syst. 25(6), pp. 599--616, Jun 2009.
[cao14] Zhibo Cao and Shoubin Dong, “Based on User-Trust to Estimate User Runtime in Backfilling”. J. Comput. Inf. Syst. 10(10), pp. 4443--4450, May 2014. Annotation: Adjust user estimates using a factor that reflects the accuracy of previous estimates.
[carvalho12] Marcus Carvalho and Francisco Brasileiro, “A User-Based Model of Grid Computing Workloads”. In 13th Intl. Conf. Grid Computing, pp. 40--48, Sep 2012.
[chen13] Junliang Chen, Bing Bing Zhou, Chen Wang andPeng Lu, Penghao Wang, and Albert Y. Zomaya, “Throughput Enhancement Through selective Time Sharing and Dynamic Grouping”. In 27th Intl. Parallel & Distributed Processing Symp. (IPDPS), pp. 1183--1192, May 2013.
[deb13] Budhaditya Deb, Mohak Shah, Scott Evans, Manoj Mehta, Anthony Gargulak, and Tom Lasky, “Towards Systems Level Prognostics in the Cloud”. In IEEE Conf. Prognostics & Health Mgmt., Jun 2013.
[deng13] Kefeng Deng, Junqiang Song, Kaijun Ren, and Alexandru Iosup, “Exploring Protfolio Scheduling for Long-Term Execution ofScientific Workloads in IaaS Clouds”. In Supercomputing, Nov 2013.
[di12] Sheng Di, Derrick Kondo, and Walfredo Cirne, “Characterization and Comparison of Cloud versus Grid Workloads”. In Intl. Conf. Cluster Comput., pp. 230--238, Sep 2012.
[di14] Sheng Di, Derrick Kondo, and Franck Cappello, “Characterizing and Modeling Cloud Applications/Jobs on a Google Data Center”. J. Supercomput. , 2014.
[esbaugh07] Bryan Esbaugh and Angela C. Sodan, “Coarse-Grain Time Slicing with Resource-Share Control in Parallel-Job Scheduling”. In 3rd High Perf. Comput. & Comm., Springer-Verlag, Lect. Notes Comput. Sci. vol. 4782, pp. 30--43, Sep 2007. Annotation: Vary the time slices at different times and for different job classes to control the allocations.
[etinski12] M. Etinski, J. Corbalan, J. Labarta, and M. Valero, “Parallel Job Scheduling for Power Constrained HPC Systems”. Parallel Comput. 38(12), pp. 615--630, Dec 2012. Annotation: Using dynamic voltage scaling to run different jobs at different speeds.
[feitelson07a] Dror G. Feitelson, “Locality of sampling and diversity in parallel system workloads”. In 21st Intl. Conf. Supercomputing (ICS), pp. 53--63, Jun 2007. Annotation: Suggests that distributions of workload attributes as seen on short timescales may be quite different from those on a long timescale. The divergence between the distributions can be used as a metric to quantify this effect, and localized sampling (or rather repetitions of a single item) from the global distribution can be used to generate it.
[feitelson08] Dror G. Feitelson, “Looking at Data”. In 22nd Intl. Parallel & Distributed Processing Symp. (IPDPS), Apr 2008. Annotation: Examples of the importance of using real data rather than assumptions.
[feitelson09] Dror G. Feitelson and Edi Shmueli, “A Case for Conservative Workload Modeling: Parallel Job Scheduling with Daily Cycles of Activity”. In 17th Modeling, Anal. & Simulation of Comput. & Telecomm. Syst. (MASCOTS), Sep 2009. Annotation: Shows that a user-aware scheduler that prioritizes interactive parallel jobs only leads to improved performance when daily cycles are included in the workload model, because otherwise it does not have when to run the low priority non-interactive jobs.
[feitelson:pwa] Dror G. Feitelson, Dan Tsafrir, and David Krakov, Experience with the Parallel Workloads Archive. Technical Report 2012-6, Hebrew University, Apr 2012.
[folling09] Alexander Fölling, Christian Grimme, Joachim Lepping, and Alexander Papaspyrou, “Decentralized grid scheduling with evolutionary fuzzy systems”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 5798, pp. 16--36, 2009.
[garg11] Saurabh Kumar Garg, Chee Shin Yeo, and Rajkumar Buyya, “Green Cloud Framework for Improving Carbon Efficiency of Clouds”. In EuroPar, Lect. Notes Comput. Sci. vol. 6852, pp. 491--502, Aug 2011.
[goh08] Lee Kee Goh and Bharadwaj Veeravalli, “Design and Performance Evaluation of Combined First-Fit Task Allocation and Migration Strategies in Mesh Multiprocessor Systems”. Parallel Comput. 34(9), pp. 508--520, Sep 2008.
[gomezm13] César Gómez-Martín, Miguel A. Vega-Rodrígez, José-Luis González-Sánchez, Javier Corral-García, and David Cortés-Polo, “Performance and Energy Aware Scheduling Simulator for High-Performance Computing”. In 7th Iberian Grid Infrastructure Conf., pp. 17--29, Sep 2013.
[guim09] Francesc Guim, Ivan Rodero, and Julita Corbalan, “The Resource Usage Aware Backfilling”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 5798, pp. 59--79, 2009.
[hao14] Yongsheng Hao, Guanfeng Liu Rongtao Hou, Yongsheng Zhu, and Junwen Lu, “Performance Analysis of Gang Scheduling in a Grid”. J. Netw. & Syst. Mgmt. , 2014.
[huang13a] Kuo-Chan Huang, Tse-Chi Huang, Yuan-Hsin Tung, and Pin-Zei Shih, “Effective Processor Allocation for Moldable Jobs with Application Speedup Model”. In Advances in Intelligent Systems and Applications, Springer-Verlag, vol. 2 pp. 563--572, Dec 2013.
[huang13b] Kuo-Chan Huang, Tse-Chi Huang, Mu-Jung Tsai, and Hsi-Ya Chang, “Moldable Job Scheduling for HPC as a Service”. In 8th Future Information Technology, Springer-verlag, Lect. Notes Elect. Eng. vol. 276, pp. 43--48, Sep 2013.
[huang13c] Kuo-Chan Huang, Tse-Chi Huang, Mu-Jung Tsaia, Hsi-Ya Chang, and Yuan-Hsin Tung, “Moldable Job Scheduling for HPC as a Service with Application Speedup Model and Execution Time Information”. J. Convergence 4(4), pp. 14--22, Dec 2013.
[iosup08] Alexandru Iosup, Hui Li, Mathieu Jan, Shanny Anoep, Catalin Dumitrescu, Lex Wolters, and Dick H. J. Epema, “The Grid Workloads Archive”. Future Generation Comput. Syst. 24(7), pp. 672--686, May 2008.
[kleineweber11] Christoph Kleineweber, Axel Keller, Oliver Niehörster, and André Brinkman, “Rule-Based Mapping of Virtual Machines in Clouds”. In 19th Euromicro Conf. Parallel, Distrib. & Network-Based Proc., pp. 527--534, Feb 2011.
[klusacek10] Dalibor Klusávcek and Hana Rudová, “The Importance of Complete Data Sets for Job Scheduling Simulations”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 6253, pp. 132--153, 2010. Annotation: Uses the Metacentrum log and others to demonstrate that including information about failures and specific job requirements leads to more complicated scheduling decisions and reduced performance.
[klusacek12] Dalibor Klusávcek and Hana Rudová, “Performance and Fairness for Users in Parallel Job Scheduling”. In Job Scheduling Strategies for Parallel Processing, Walfredo Cirne and others, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 7698, pp. 235--252, 2012.
[krakov12] David Krakov and Dror G. Feitelson, “High-Resolution Analysis of Parallel Job Workloads”. In Job Scheduling Strategies for Parallel Processing, Walfredo Cirne and others, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 7698, pp. 178--195, May 2012. Annotation: Suggests the use of heatmaps where the X axis is the load experienced by each job, and the Y axis is its performance. This shows the pattern of how jobs distribute.
[kubert12] Roland Kübert and Stefan Wesner, “High-Performance Computing as a Service with Service Level Agreements”. In 9th Intl. Conf. Services Comput., pp. 578--585, Jun 2012.
[kumar12] Rajath Kumar and Sathish Vadhiyar, “Identifying Quick Starters: Towards an Integrated Framework for Efficient Predictions of Queue Waiting Times of Batch Parallel Jobs”. In Job Scheduling Strategies for Parallel Processing, Walfredo Cirne and others, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 7698, pp. 196--215, 2012.
[kurowski12] Krzysztof Kurowski, Ariel Oleksiak, Wojciech Piatek, and Jan We¸glarz, “Impact of Urgent Computing on Resource Management Policies, Schedules and Resources Utilization”. Procedia Comput. Sci. 9, pp. 1713--1722, 2012.
[leal13] Katia Leal, “Self-Adjusting Resource Sharing Policies in Federated Grids”. Future Generation Comput. Syst. 29(2), pp. 488--496, Feb 2013.
[lee07] Cynthia Bailey Lee and Allan E. Snavely, “Precise and Realistic Utility Functions for User-Centric Performance Analysis of Schedulers”. In 17th Intl. Symp. High Performance Distributed Comput. (HPDC), pp. 107--116, Jun 2007. Annotation: Define synthetic utility functions giving importance to users as function of resopnse time, based on data of how such functions generally look. Then define a scheduler that uses genetic algorithms to schedule jobs so as to optimize utility.
[liang13] Aihua Liang, Limin Xiao, and Li Ruan, “Adaptive Workload Driven Dynamic Power Management for High Performance Computing Clusters”. Comput. & Elect. Eng. 39(7), pp. 2357--2368, Oct 2013.
[lindsay12] A. M. Lindsay, M. Galloway-Carson, C. R. Johnson, D. P. Bunde, and V. J. Leung, “Backfilling with Guarantees Made as Jobs Arrive”. Concurrency & Computation -- Pract. & Exp. , 2012. Annotation: Conservative backfilling with the added feature that when the schedule is compressed jobs are prioritized based on a selected desirable trait.
[lingrand09] Diane Lingrand, Johan Montagnat, Janusz Martyniak, and David Colling, “Analyzing the EGEE Production Grid Workload: Application to Jobs Submission Optimization”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 5798, pp. 37--58, 2009. Annotation: Detailed analysis of EGEE data, and in particular job failures and resubmission strategies of users.
[liux12] Xiaocheng Liu, Chen Wang, Xiaogang Qiu, Bing Bing Zhou, Bin Chen, and Albert Y. Zomaya, “Backfilling under Two-Tier Virtual Machines”. In Intl. Conf. Cluster Comput., pp. 514--522, Sep 2012. Annotation: Use two VMs per CPU, and schedule the foreground VM using EASY and the background VM using SJF.
[liuz10] Zhuo Liu, Aihua Liang, and Limin Xiao, “A Parallel Workload Model and its Implications for Maui Scheduling Policies”. In 2nd Intl. Conf. Comput. Modeling & Simulation, pp. 384--389, Jan 2010.
[lix13] Xin Li, Zhuzhong Qian, Sanglu Lu, and Jie Wu, “Energy Efficient Virtual Machine Placement Algorithm with Balanced and Improved Resource Utilization in a Data Center”. Math. & Comput. Modelling 58(5-6), pp. 1222--1235, Sep 2013.
[liy07] Yawei Li, Prashasta Gujrati, Zhiling Lan, and Xian-he Sun, “Fault-Driven Re-Scheduling for Improving System-Level Fault Resilience”. In Intl. Conf. Parallel Processing (ICPP), Sep 2007.
[minh09] Tran Ngoc Minh and Lex Wolters, “Modeling Parallel System Workloads with Temporal Locality”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 5798, pp. 101--115, 2009.
[minh11] Tran Ngoc Minh and Lex Walters, “Towards a Profound Analysis of Bags-of-Tasks in Parallel Systems and Their Performance Impact”. In 20th Intl. Symp. High Performance Distributed Comput. (HPDC), pp. 111-122, Jun 2011.
[ming13] Wu Ming, Yang Jian, and Ran Yongyi, “Dynamic Instance Provisioning Strategy in an IaaS Cloud”. In 32nd Chinese Control Conf., pp. 6670--6675, Jul 2013.
[neves12] Marcelo Veiga Neves, Tiago Ferreto, and César De Rose, “Scheduling MapReduce Jobs in HPC Clusters”. In EuroPar, pp. 179--190, Aug 2012.
[niu12] Shuangcheng Niu, Jidong Zhai, Xiaosong Ma, Mingliang Liu, Yan Zhai, Wenguang Chen, and Weimin Zheng, “Employing Checkpoint to Improve Job Scheduling in Large-Scale Systems”. In Job Scheduling Strategies for Parallel Processing, Walfredo Cirne and others, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 7698, pp. 36--55, 2012.
[pascual09] Jose Antonio Pascual, Javier Navaridas, and Jose Miguel-Alonso, “Effects of Topology-Aware Allocation Policies on Scheduling Performance”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 5798, pp. 138--156, 2009.
[ranjan08] Rajiv Ranjan, Aaron Harwood, and Rajkumar Buyya, “A Case for Cooperative and Incentive-Based Federation of Distributed Clusters”. Future Generation Comput. Syst. 24(4), pp. 280--295, Apr 2008.
[shah10] Syed Nasir Mehmood Shah, Ahmad Kamil Bin Mahmood, and Alan Oxley, “Analysis and evaluation of grid scheduling algorithms using real workload traces”. In Intl. Conf. Mgmt. Emergent Digital EcoSystems, pp. 234--239, Oct 2010.
[shai13] Ohad Shai, Edi Shmueli, and Dror G. Feitelson, “Heuristics for Resource Matching in Intel's Compute Farm”. In Job Scheduling Strategies for Parallel Processing, Walfredo Cirne and Narayan Desai, (ed.), Springer-Verlag, 2013.
[sheikhalishahi11] Mehdi Sheikhalishahi, Manoj Devare, Lucio Grandinetti, and Demetrio Laganà, “A General-purpose and Multi-level Scheduling Approach in Energy Efficient Computing”. In 1st Proc. Intl. Conf. Cloud Computing and Services Science, pp. 37--42, May 2011.
[sheikhalishahi12] Mehdi Sheikhalishahi, Ignacio Martín Llorente, and Lucio Grandinetti, “Energy Aware Consolidation Policies”. In Advances in Parallel Computing, Vol. 22: Applications, Tools and Techniques on the Road to Exascale Computing, IOS Press, pp. 109--116, 2012.
[sheikhalishahi14] Mehdi Sheikhalishahi, Lucio Grandinetti, Richard M. Wallace, and Jose Luiz Vazquez-Poletti, “Autonomic Resource Contention-Aware Scheduling”. spe , 2014.
[shih13] Po-Chi Shih, Kuo-Chan Huang, Che-Rung Lee, I-Hsin Chung, and Yeh-Ching Chung, “TLA: Temporal Look-Ahead Procesor Allocation Method for Heterogeneous Multi-Cluster Systems”. J. Parallel & Distributed Comput. , 2013. Annotation: Simulate allocation options to get idea of expected performance taking cluster heterogeneity into account.
[shmueli07] Edi Shmueli and Dror G. Feitelson, “Uncovering the Effect of System Performance on User Behavior from Traces of Parallel Systems”. In 15th Modeling, Anal. & Simulation of Comput. & Telecomm. Syst. (MASCOTS), pp. 274--280, Oct 2007. Annotation: User session lengths are correlated with response times: a long response time is a good predictor for a session end. Slowdown is not such a good predictor.
[shmueli09] Edi Shmueli and Dror G. Feitelson, “On Simulation and Design of Parallel-Systems Schedulers: Are We Doing the Right Thing?”. IEEE Trans. Parallel & Distributed Syst. 20(7), pp. 983--996, Jul 2009. Annotation: User behavior induces a feedback cycle from system performance to the generation of additional jobs, and this has to be taken into account in evaluations and can also lead to improved designs.
[sodan09] Angela C. Sodan, “Adaptive Scheduling for QoS Virtual Machines under Different Resource Allocation--Performance Effects and Predictability”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 5798, pp. 259--279, 2009.
[sodan10] Angela C. Sodan and Wei Jin, “Backfilling with Fairness and Slack for Parallel Job Scheduling”. In J. Physics: Conf. Ser., High Perf. Comput. Symp., vol. 256 2010.
[sodan11] A. C. Sodan, “Service Control with the Preemptive Parallel Job Scheduler Scojo-PECT”. Cluster Comput. 14(2), pp. 165--182, Jun 2011.
[talby07] David Talby, Dror G. Feitelson, and Adi Raveh, “A Co-Plot Analysis of Logs and Models of Parallel Workloads”. ACM Trans. Modeling & Comput. Simulation 12(3), Jul 2007. Annotation: A statistical analysis of the similarity of various workload logs and models, showing that the models fall in the same space as the original logs, but parameterization is needed to capture the specific characteristics of any one log. Two dimensions seem to suffice.
[tang10] Wei Tang, Narayan Desai, Daniel Buettner, and Zhiling Lan, “Analyzing and Adjusting User Runtime Estimates to Improve Job Scheduling on Blue Gene/P”. In 24th Intl. Parallel & Distributed Processing Symp. (IPDPS), Apr 2010. Annotation: Which part of the scheduling is most sensitive to inaccurate runtime estimates, and how to improve it using historical data.
[tang11] Wei Tang, Zhiling Lan, Narayan Desai, Daniel Buettner, and Yongen Yu, “Reducing Fragmentation on Torus-Connected Supercomputers”. In Intl. Parallel & Distributed Processing Symp. (IPDPS), pp. 828--839, May 2011.
[tang13] Wei Tang, Narayan Desai, Daniel Buettner, and Zhiling Lan, “Job Scheduling with Adjusted Runtime Estimates on Production Supercomputers”. J. Parallel & Distributed Comput. 73(7), pp. 926--938, Jul 2013. Annotation: Predict each jobs accuracy (ratio of actual to requested time) based on historical data, and use the adjusted runtime (i.e. the request multiplied by the adjustment factor) in scheduling decisions.
[thebe09] Ojaswirajanya Thebe, David P. Bunde, and Vitus J. Leung, “Scheduling Restartable Jobs with Short Test Runs”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 5798, pp. 116--137, 2009.
[tian14] Wenhong Tian and Chee Shin Yeo, “Minimizing Total Busy Time in Offline Parallel Scheduling with Application to Energy Efficiency in Cloud Computing”. Concurrency & Computation -- Pract. & Exp. , 2014.
[toosi11] Adel Nadjaran Toosi, Rodrigo N. Calheiros, Ruppa K. Thulasiram, and Rajkumar Buyya, “Resource Provisioning Policies to Increase IaaS Provider's Profit in a Federated Cloud environment”. In 13th Intl. Conf. High Performance Comput. & Commun., pp. 279--287, Sep 2011.
[tsafrir07a] Dan Tsafrir, Yoav Etsion, and Dror G. Feitelson, “Backfilling Using System-Generated Predictions Rather Than User Runtime Estimates”. IEEE Trans. Parallel & Distributed Syst. 18(6), pp. 789--803, Jun 2007. Annotation: Suggests using the average of the last two jobs by the same user as a runtime prediction. requires updating the prediction when new information becomes available, e.g. when the job runs longer than the previous prediction.
[tsafrir07b] Dan Tsafrir, Keren Ouaknine, and Dror G. Feitelson, “Reducing Performance Evaluation Sensitivity and Variability by Input Shaking”. In 15th Modeling, Anal. & Simulation of Comput. & Telecomm. Syst. (MASCOTS), pp. 231--237, Oct 2007. Annotation: Run the simulation many (e.g. hundreds) of times with slightly different input, to see the distribution of results.
[tsafrir10] Dan Tsafrir, “Using Inaccurate Estimates Accurately”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer, Lect. Notes Comput. Sci. vol. 6253, pp. 208--221, 2010.
[utrera12] Gladys Utrera, Siham Tabik, Julita Corbalan, and Jesús Labarta, “A Job Scheduling Approach for Multi-Core Clusters Based on Virtual Malleability”. In 18th EuroPar, pp. 191--203, Aug 2012.
[vandenbossche11] Ruben Van den Bossche, Kurt Vanmechelen, and Jan Broeckhove, “An Evaluation of the Benefits of Fine-Grained Value-Based Scheduling on General Purpose Clusters”. Future Generation Comput. Syst. 27(1), pp. 1--9, Jan 2011.
[verma08] Akshat Verma, Puneet Ahuja, and Anindya Neogi, “Power-Aware Dynamic Placement of HPC Applications”. In 22nd Intl. Conf. Supercomputing (ICS), pp. 175--184, Jun 2008.
[yang13] Xu Yang, Zhou Zhou, Sean Wallace, Zhiling Lan, Wei Tang, Susan Coghlan, and Michael E. Papka, “Integrating Dynamic Pricing of Electricity into Energy aware Scheduling for HPC Systems”. In Supercomputing, Nov 2013.
[yeo10] Chee Shin Yeo, Srikumar Venugopal, Xingchen Chua, and Rajkumar Buyya, “Autonomic metered pricing for a utility computing service”. Future Generation Comput. Syst. 26(8), pp. 1368--1380, Oct 2010.
[yuan11] Yulai Yuan, Yongwei Wu, Qiuping Wang, Guangwen Yang, and Weimin Zheng, “Job Failures in High Performance Computing Systems: A Large-Scale Empirical Study”. Comput. & Math. with Applications 62, 2011.
[zakay12] Netanel Zakay and Dror G. Feitelson, “On Identifying User Session Boundaries in Parallel Workload Logs”. In Job Scheduling Strategies for Parallel Processing, Walfredo Cirne and others, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 7698, pp. 216--234, 2012. Annotation: Suggests using long interarrival times to identify session breaks rather than long think times, because parallel jobs can be very long.
[zakay13] Netanel Zakay and Dror G. Feitelson, “Workload Resampling for Performance Evaluation of Parallel Job Schedulers”. In 4th Intl. Conf. Performance Engineering, pp. 149--159, Apr 2013.
[zeng09] Xijie Zeng and Angela C. Sodan, “Job Scheduling with Lookahead Group Matchmaking for Time/Space Sharing on Multi-Core Parallel Machines”. In Job Scheduling Strategies for Parallel Processing, Eitan Frachtenberg and Uwe Schwiegelshohn, (ed.), Springer-Verlag, Lect. Notes Comput. Sci. vol. 5798, pp. 232--258, 2009.
[zilber05] Julia Zilber, Ofer Amit, and David Talby, “What is Worth Learning from Parallel Workloads? A User and Session Based Analysis”. In 19th Intl. Conf. Supercomputing (ICS), pp. 377--386, Jun 2005.
[zheng11] Ziming Zheng, Li Yu, Wei Tang, Zhiling Lan, Rinku Gupta, Narayan Desai, Susan Coghlan, and Daniel Buettner, “Co-Analysis of RAS Log and Job Log on Blue Gene/P”. In Intl. Parallel & Distributed Processing Symp. (IPDPS), pp. 840--851, May 2011.