Recommendation System (سیستم های توصیه گر): تفاوت میان نسخهها
مریم اولیایی (بحث | مشارکتها) |
مریم اولیایی (بحث | مشارکتها) |
||
| (یک نسخهٔ میانیِ ایجادشده توسط همین کاربر نشان داده نشد) | |||
| خط ۱۰۹: | خط ۱۰۹: | ||
زنده بودن به غنای محیط تعاملی باز می گردد که از طریق آن چه اطلاعاتی را می توان ارائه کرد. که داراری دو عنصر مهم است. وسعت حسی اشاره به تعداد ابعاد حسی به طور همزمان ارائه شده دارد.عمق حسی اشاره به تفکیک پذیری در هر کانال ادراکی دارد. | زنده بودن به غنای محیط تعاملی باز می گردد که از طریق آن چه اطلاعاتی را می توان ارائه کرد. که داراری دو عنصر مهم است. وسعت حسی اشاره به تعداد ابعاد حسی به طور همزمان ارائه شده دارد.عمق حسی اشاره به تفکیک پذیری در هر کانال ادراکی دارد. | ||
تعامل، این را بیان می کنند که کاربر تا چه اندازه می تواند در اصلاح شکل و محیط واسطه در زمان واقعی شرکت کند. | تعامل، این را بیان می کنند که کاربر تا چه اندازه می تواند در اصلاح شکل و محیط واسطه در زمان واقعی شرکت کند. | ||
<big>intrinsic attributes:</big> ویژگی های ذاتی می تواند در میان محصولات مختلف متفاوت باشد. در اینجا ویژگی های ذاتی به سه نوع تقسیم شده اند. 1- ظاهر، اشاره به صفاتی که به نمایندگی سطحی محصولات مربوط می شوند دارد مانند الگوها، شکل، اندازه و غیره.2- ماده، به ویژگی هایی که محصول از آن ساخته اشاره دارد مانند خواص پارچه، وزن و غیره. 3-قابلیت ها، به ویژگی هایی که محصول برای ما سودمندی دارد اشاره می کند یا این که بر روی محصول چه عملی می توان انجام داد و یا این که اعمالی که آن محصول برای ما انجام می دهد. | |||
<big>Extrinsic attributes:</big> بر خلاف ویژگی های ذاتی، این دسته از ویژگی ها(مانند قیمت، نوع محصول و غیره) هیچ تاثیر مستقیمی بر کیفیت درک شده از محصول ندارند.آنها بیشتر زمانی که اطلاعات در رابطه با ویژگی های ذاتی ناقص است به عنوان نشانه برای پی بردن به کیفیت محصول استفاده می شوند. | |||
==نتیجه گیری== | ==نتیجه گیری== | ||
نسخهٔ کنونی تا ۵ فوریهٔ ۲۰۱۶، ساعت ۰۲:۵۹
سیستم های توصیه گر
چکیده
رشد بی سابقه تکنولوژي جدید اینترنت در سالهاي اخیر، باعث ایجاد برنامه هاي کاربردي بسیار زیادي در زمینه تجارت الکترونیکی شده است. وجود برنامه هاي کاربردي در زمینه B2C و B2B نیاز به ارتباط موثر بین ماشین ها را دارد. یکی از مهمترین برنامه هاي کاربردي سیستم هاي توصیه گر می باشد. سیستمهاي پیشنهاد دهنده یک نوع ویژه از سیستم هاي فیلتر اطلاعات است، که در آن آیتم ها را، بر اساس اینکه چه آیتمی براي کاربر جذاب است، از یک مجموعه بزرگ از آیتم ها و کاربران فیلتر می کنند. توصیه فرایندی است که نقش مهمی در بسیار ی از برنامه های کاربردی وب بازی می کند سيستم هاي توصيه گر سيستم هايي هستند که سعي دارند بر اساس عملکرد، سليقه هاي شخصي، رفتارهاي کاربر و بسته به زمينه اي که در آن مورد استفاده قرار گرفته اند، به هر کاربر پيشنهادهايي را ارائه دهند که با تمايلات شخصي وي تطابق داشته و وي را در فرايند تصميم گيري ياري نمايند. با رشد روز افزون تجارت در دنياي وب، آموزش الکترونيکي، افزايش ارتباط و اشتراک کاربران با يکديگر و پيدايش شبکه هاي اجتماعي، لزوم طراحي و پياده سازي چنين سيستم هايي غير قابل انکار است. هدف اصلی بررسی چالش های مختلفی است در رابطه با تکنیک های مختلفی که در زمینه توصیه گری وجود دارد. با بررسی این مشکلات می توانیم کیفیت سیستم های توصیه گری را افزایش دهیم با اختراع روش های و متد های جدید که می توانند در این حوزه کاربردی باشند.
مقدمه
دراواسط دهه 1990 ، زمانیکه محققان تحقیقاتشان را در زمینه سیستمهاي پیشنهاد دهنده آغاز نمودند این تحقیقات بطور روشنی روي ساختارهاي نرخ گذاري متمرکز بود. دراغلب فرمول ها، مسایل پیشنهاد دهی با تخمین نرخ که معمولا توسط کاربران داده می شد، کاهش می یافت. تخمین ها معمولا براساس نرخهاي داده شده به آیتمها توسط کاربر واطلاعات دیگرکه بصورت قراردادي وجود داشت زده می شد. دراینصورت آیتمهایی به کاربر پیشنهاد می شد که بالاترین نرخ را داشتند. بطور قراردادي مسئله پیشنهاد دهی بصورت زیر فرمول بندي می کنیم.
دراین روش C را به عنوان همه کاربران و S را به عنوان همه آیتمهاي ممکن مثل کتاب، فیلم، رستوران و ...که می تواند به کاربر پیشنهاد شود درنظر می گیریم. فضاي S از آیتمهاي ممکن می تواند خیلی بزرگتر باشد و دامنه اي بین صد، هزاران S به کاربر پیشنهاد شود درنظر می گیریم. فضاي یا حتی میلیونها آیتم در هر کاربردي باشد؛ مثل پیشنهاد کتاب یا سی دي که می تواند در بعضی موارد فضایی میلیونی داشته باشد. تابع سودمندي u، سودمندي آیتم s را براي کاربر c بیان می کند. مجموعه کل سفارشات را با R نشان داده که بصورت C*S->R تعریف می نماییم. در سیستم های توصیه گر سودمندی آیتم ها از طریق امتیازی که به آنها داده می شود مشخص می شود که این موضوع را نشان می دهد که یک کاربر مشخص به چه صورت به آیتم مشخصی علاقه دارد.
رتبه بندی کاربر در تجارت الکترونیک برای سیستم های پیشنهاد دهنده امر مهمی است که بر اساس آن بتوانیم توصیه های باکیفیتی را در رابطه با محصولات به کاربر ارائه کنیم. هرچند کاربران می توانند دارای انگیزه کافی برای رتبه دهی نباشند و رتبه بندی تنها بعد از خرید اتفاق بیفتد. که این امر باعث می شود که اطلاعات کافی برای ارائه مدل جهت رتبه بندی نداشته باشیم و تاثیر سیستم های پیشنهاد دهنده به تاخیر بیفتد همانند مشکلات شناخته شده مثل data sparsity و cold start
data sparsity به موضوع سختی در یافتن مشتریان قابل اعتماد اشاره میکند از زمانی که مشتریان به طور کلی تنها به بخش کوچکی از اقلام رای می دهند، در حالی که cold start به سختی ارائه توصیه مناسب برای کاربرانی که تنها به اقلام کمی امتیاز داده اند مثل کمتر از 5 قلم اشاره دارد.
هر چند بسیاری از روش ها با افزایش استفاده از رتبه بندی های موجود یا با استفاده از اطلاعات اضافی به این مشکلات اشاره کرده اند، تعداد معدودی از محققات برای کاهش ذاتی این مشکلات از طریق استخراج رتبه بندی کاربر تلاش کرده اند به عبارت دیگر محیط واقعیت مجازی توجه ویژه ای را به خود جلب کرده است. به دلیل توانایی این رسانه در مجهز کردن کاربران به تجربه های مجازی همه جانبه و تعامل با محصولات مجازی، کاربر می تواند رسانه غنی تری را تجربه کند. که در ادامه به بیان منبع اطلاعاتی جدیدی به نام prior rating می پردازیم که بر اساس تجربه محصولات مجازی ساخته شده است. که آن را می توان قبل از خرید کاربر از طریق تعاملات کاربر با محیط مجازی بدست آورد.هدف این تحقیق بررسی مفهوم و ماهیت prior rating و سودمندی آن در مواجهه با مسائلی مانند data sparsity و cold start است.
بررسی ادبیات موضوع
روش های مختلفی برای حل data sparsity و cold start ارائه شده اند.از دیدگاه منابع اطلاعات ، آنها را به دو دسته تقسیم می کنیم. در دسته اول اتخاذ رتبه دهی اطلاعات دو نوع روش وجود دارد بر اساس حافظه و بر اساس مدل روش براساس حافظه ، نویسندگان متعددی معیارهای شباهت جدیدی را برای مدل کردن بهتر همبستگی کاربران برای حل مسائلی که نگرانی داشتند با توجه به ناکارآمدی روش های اندازه گیری سنتی ارائه کرده اند. اندازه گیری مبتنی بر تطابق را بر اساس میزان هماهنگی، ناساگاری ، رتبه های مشابه بین دو کاربر ارائه کرده اند که این اندازه گیری، اینکه تا چه اندازه دو کاربر با هم موافق هستند را اندازه گیری می کند.
اندازه گیری pip بر اساس معنا شناسی رتبه بندی توسعه داده شده است که بر اساس مجاورت، اثر ، محبوبیت آنهاست. این ایده بر این اساس است که آن کاربرانی که از نظر معنایی با هم موافقند بیشتر باید به هم شباهت داشته باشند تا آنهایی که با هم موافق نیستند.
Bobadilla اندازه گیری یکتایی رااز دیدگاه منحصر به فرد بودن اقلام طراحی کرده است دیدگاهی که پشت این قضیه است این است که رتبه بندی هایی که بر اقلام منحصر به فرد بالا موافقت کرده اند باید در محاسبه شباهت کاربران بیشتر نسبت به اقلام با منحصر به فرد بودن پایین درنظر گرفته شوند.
هر چند روش مبتنی بر حافظه مناسب پایگاه های داده ی بزرگ نیست. بر عکس روش مبتنی بر مدل دارای مقیاس پذیری بهتری نسبت به مبتنی بر حافظه است. به این دلیل که،نه تنها رتبه بندی دو کاربر بلکه برای رتبه بندی سایر کاربران هم یادگیری از ویژگی های کاربران و اقلام قابل قیاس است و بنابراین می تواند به دو مشکل cold start و data sparsity بهتر رسیدگی کند.
روش های تجزیه به عامل های ماتریس مبتنی بر نماینده را ارائه کرده است که هدف آن پیدا کردن بیشترین نماینده کاربران و آیتمه در سیستم است.بنابراین برای کاربران cold start، تمایلات آنها نی تواند از طریق پرسش درباره ی رتبه دهی به مهمترین نماینده ی آیتم استخراج شود. برای مبارزه با مشکل data sparsity روشی ارائه شده که تمایلات کاربران را بر اساس ویژگی آیتم ها از طریق به کاربردن یک مدل سلسله مراتبی بیزین شخصی یاد می گیرد که ترکیبی از تمایلات محلی و عمومی کاربر است.
به طور کلی تمام این روش ها(مبتنی بر حافظه و مبتنی بر مدل) تلاش می کنند برای ترکیب ویژگی های کاربر/آیتم به صورت یک مدل توصیه معین برای رسیدگی به مشکلات بیان شده. هر چند ویژگی های آیتم/کاربر ممکن است برای سیستم توصیه گر به علل مختلف مانند حریم خصوصی و غیره در دسترس نباشد.
بدنه ی تحقیق
سیستم های توصیه گر را به سه دسته تقسیم می کنند که در ادامه به بررسی آنها می پردازیم.
Collabrative Filtering Process
سیستم های فیلترینگ مشارکتی به این صورت عمل می کنند که بازخوردهای کاربران و امتیازهای آنها را جمع آوری می کنند و شباهت امتیاز کاربران را بررسی میکنند تا بتوانند بهترین توصیه را کنند. سیستم های فیلترینگ مشارکتی آیتم ها را بر اساس نظر سایر کاربران توصیه می کنند. هدف فیلتر مشارکتی یافتن کاربرانی است که هم عقیده با کاربر جدید هستند.سپس آیتم هاي مورد علاقه آنها را به کاربر جدید پیشنهاد می کند.
- فیلترینگ مشارکتی تمام فضای کاربر را به عنوان ماتریس امتیاز R نشان می دهد. هر کدام از درایه های این ماتریس مقدار ترجیح را نشان می دهند اگر کاربر iام به آیتم jام امتیاز داده باشد که این امتیاز ها به صورت عددی است و همین طور می تواند صفر باشد که بیان کننده این موضوع است که این فرد هنوز امتیاز نداده است.
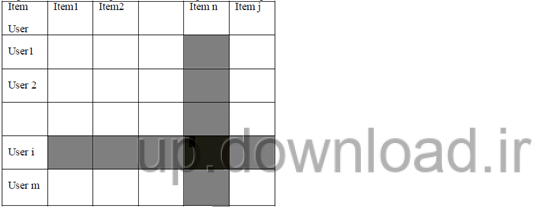
- مشکل فیلترینگ مشارکتی شامل ارزیابی یا پیش بینی امتیاز دهی اقلامی است که هنوز امتیاز دهی نشده اند . برای پیش بینی امتیاز دهی مشابهت بین کاربران از طریق روش های متفاوت محاسبه می شود .
- با استفاده از این تشابه توصیه ای که از رابط خروجی تولید می شود را می توان به دو نوع پیش بینی و توصیه تقسیم بندی کرد.
Content-Based Process
سیستم های توصیه گر مبتنی بر محتوا بر اساس علاقه کاربر و شرح محتوا آینمی را به کاربر پیشنهاد می دهد همانند سیستم هایی که برای توصیه صفحات وب ، برتامه های تلوزیون ، اخبار مقالات و غیره استفاده می شوند. تمام سیستم های توصیه گر مبتنی بر محتوا دارای وجه تشابه هایی هستند مانند شرح وضعیت آیتم ها، پروفایل کاربر و روش هایی برای مقایسه آیتم ها با پروفایل کاربران برای شناسایی این که چه چیزی برای توصیه به کاربر خاص مناسب است. سیستم های توصیه گر مبتنی بر محتوا بر اساس ویژگی های آیتم و علایق کاربران که در پروفایل آنها مشخص شده است پیشنهاد مناسب را می دهند. اصولا پروفایل های شخصی به صورت اتوماتیک از طریق بازخورد از کاربر ساخته می شوند و نوع آیتم هایی را که کاربر به آن علاقه دارند را توصیف می کنند. برای تعیین این که چه آیتمی به کاربر توصیه شود، اطلاعات جمع آوری شده از کاربران را با ویژگی محتوای آیتم ها مقایسه می شوند .
- این سیستم دارای پایگاه داده بزرگی متشکل از مواردی که توصیه می شوند و ویژگی های آیتم ها که آنها به عنوان مشخصات آیتم ها نامیده می شوند.
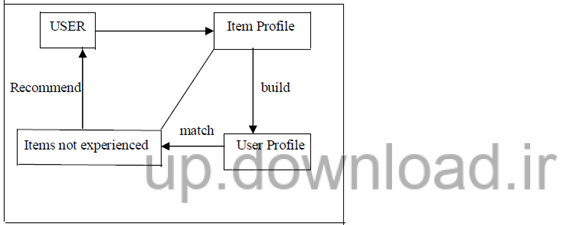
- کاربران اطلاعاتی در رابطه با ترجیحاتشان ارائه می کنند. سیستم با ترکیب اطلاعات آیتم و ترجیح کاربر پروفایل کاربر را می سازد.
- بر اساس اطلاعات موجود در پروفایل کاربر مورد نظر، سیستم مناسب تری آیتم را به کاربر توصیه می کند.
در واقع می توانیم با ویژگی های اقلام و کاربران توصیه های بهتر شخصی را به آنها پیشنهاد کند. پروفایل آیتم ها بر اساس مهمترین ویژگی آنها تعیین می شود. به عنوان مثال یک فیلم می تواند بر اساس عنوان ، ژانر ، زبان ، کشور ، بازیگران و غیره تقسیم شود. بر اساس وزن روش، تشابه بین دو آیتم می تواند اندازه گیری شود. بسته به حوزه ویژگی ها می توانند هم بر ارزش مقدار بولین و هم براساس ارزش محدود شده بیان شوند.
به عنوان مثال این را درنظر بگیرید که می خواهیم مجموعه ای از مقالات روزنامه در رابطه با موضوعات مختلف را تحلیل کنیم. درحالی که ارزش بولین میتواند براساس کلمه ای که در مقاله وجود دارد و یا خیر تعیین شود و مقدار int میتواند تعداد دفعاتی که یک کلمه تکرار می شود را بیان کند.
برای ساخت پروفایل کاربر می توان از اطلاعات کاربر استفاده کرد. در پایگاه داده فیلم، کاربران براساس ویژگی های دموگرافیکشان مانند سن، جنسیت، اشتغال، کد پستی توصیف می شوند.اطلاعات کاربران توسط خودشان ارائه می شود و یا این که این اطلاعات به صورت ضمنی توسط عامل جمع آوری می شوند.
- اطلاعات آشکار جمع آوری به ورودی که کاربران وارد می کنند بستگی دارد.یک روش رایج بازخورد این ست که به کاربران اجازه دهیم که نظر خودشان را در رابطه با انتخاب یک مقدار از محدوده بیان کنند.هرچند، پرکردن یک فرم یا کلیک کردن بر روی چک باکس ها می تواند برای کاربران یک بار اضافه محسوب شود.پروفایل ها ممکن است مبهم باشند به این دلیل که کاربران علاقه به صرف زمان طولانی برای ارائه اطلاعات خودشان ندارند و یا این که اطلاعات کاربران به روز نمی باشد.
- بازخورد ضمنی نیاز به مداخله اضافی کاربران در طی فرآیند ساخت پروفایل ندارد و به صورت خودکار تعاملات کاربر با سیستم را به روز رسانی می کند
Hybrid Process
برخی از سیستمهاي توصیه گر از روش دیگري که ترکیبی از دو روش مبتنی بر محتوا و فیلتر مشارکتی است، استفاده می نمایند تا محدودیتهاي دو روش قبلی را کاهش دهند. راههاي مختلفی براي ترکیب دو روش پیشنهاد شده است که درادامه دسته بندي می کنیم.این روشها ممکن است خروجی های متفاوتی را تولید کنند، روش های مختلف پیوند زدن عبارتند از :
- اجرای جداگانه هر کدام از روش هایCF و CB و ترکیب پیش بینی آنها.
- ترکیب قسمتی از ویژگی های مبتنی بر محتوا در روش همکارانه
- ترکیب قسمتی از ویژگی های مشارکتی در روش مبتنی بر محتوا
- ساخت یک مدل وحدت عمومی که ویژگی های هر دو روش مبتنی بر محتوا و مشارکتی با هم ترکیب کند.
برخی از موانعی که در سیستم های توصیه گر وجود دارند:
Sparsity Problem
یکی از مشکلات اصلی در سستم های توصیه گر به حساب می آیند و data sparsity تاثیر بسازی در کیفیت توصیه دارد.علت اصلی data sparsity این است که بیشتر کاربران به آیتم ها رتبه نمی دهند و رتبه های در دسترس معمولا پراکنده هستند.فیلترینگ مشارکتی از این مشکل رنج می برد به این علت که به ماتریس رتبه دهی وابسته است.
Cold Start problem
به موقعیتی باز می گردد که یک کاربر جدید یا یک آیتم جدید به سیستم وارد شده است. در این وضعیت بسیار سخت هست که پیشنهاداتی را به کاربر جدید که اطلاعات اندکی در رابطه با آن داریم ارائه کنیم. فلترینگ مبتنی بر محتوا می تواند توصیه هایی را در وضعیت آیتم های جدید ارائه کند زیرا به رتبه دهی های قبلی وابسته نمی باشد .
در ادامه به توضیح روشی برای حل این دو مشکل می پردازیم .
Prior ratings
به عنوان ارزیابی کاربران و یا قضاوت آنها در رابطه با تمایل آنها نسبت به محصولاتی که در تجربه ای که نسبت به محصولات مجازی بدست آورده اند و به تمایل انها به وضعیت روانی و احساسی آنها نسبت به تعاملاتشان در رابطه با محیط محصولات مجازی باز می گردد.از این جهت prior rating در محیط واسطه اتفاق می افتد و می تواند آن را قبل از خرید و یا بعد از خرید صادر کرد. بنابراین، اگر چه بر محیط مجازی تمرکز کرده ایم ولی prior rating می تواند در سایر محیط های واسطه هم داده شوند مثل واقعیت افزوده تا زمانی که می توانیم تجربه ی محصولات مجازی قابل اعتماد را ارائه کنیم.یه امتیاز دهی استاندارد اشاره شده است که ناشی از تجربه ی محصولات قبلی است به نام poiserior raiting که آن را poisterior نامیدند. منظور تجربه ی قابل لمس از محصول مشهود است که از طریق استفاده از محصول در محیط فیزیکی می باشد. از زمانی که تجربه ی محصولات قابل لمس تنها می توانند به صورت کامل پس از خرید محصول اتفاق بیفتد، امتیاز poisterior همیشه امتیاز بعد از خرید است. prior raiting و posterior به صورت متمایز و جامع هستند که هر کدام از آنها تجربه ی متفاوتی را منعکس می کنند .برای محصولاتی که قابل لمس نیستند مثل فیلم ، کاربران تنها آنها را می توانند از طریق رسانه های مجازی تجربه کنند. لزوما امتیاز کاربران از نوع prior است.
دو نوع محیط رسانه مورد بررسی قرار گرفته است، محیط وب سایت های سنتی دو بعدی و وب سایت های سه بعدی این دو رسانه در غنا با همدیگر متفاوت هستند . وب سایت های دو بعدی تنها تعداد محدودی از رسانه و تعامل بین کاربران را مورد حمایت خودشان دارند. تعاملات در لحظه رتبه دهی مجازی این حس را به کاربران القا می کند که آنها در محیط رسانه قرار دارند و تجربه خرید همانند دنیای واقعی بدست می آورند.کاربران می توانند محصولاتی که به صورت سه بعدی هستند را شخصی سازی کنند، بچرخانند و حتی می توانند آن را بپوشند و مشاهده تغییرات بپردازند.که ای موضوع به عنوان تجربه ی محصولات مجازی غنی در نظر گرفته می شوند که کاربران در محیط مجازی به دست می آورند.این موضوع بیان شده است که واقعیت مجازی می تواند انگیزه کافی به کاربران بدهد تا آنها به محصولات مورد علاقشان قبل از خرید امتیاز دهند و از این رو باعث می شود تصمیمات خرید با اطلاعات بیشتر در طول خرید واقعیت مجازی اتخاذ کنند . پس می توان این را بیان کرد که کاربران علاقه بیشتری دارند که به آیتم هایی که قبل از خرید در واقعیت مجازی با آنها تعامل کردن نسبت به محیط دوبعدی امتیاز دهند.


هر چند که prior rating می تواند در هر دو محیط واقعیت مجازی و وبسایت های سنتی تا زمانی که رابط کاربر امکان رتبه بندی را فراهم می کند ارسال کرد اما ممکن است سطح اعتماد متفاوت باشد.این مووع می تواند ناشی از رسانه ی محدود و میزان تعاملاتی که در وبسایت های سنتی وجود دارد باشد، کاربران ممکن است اطلاعات مناسب کمی برای رتبه دهی نسبت به محیط واقعیت مجازی در دسترس داشته باشند. همچنین محصولات مجازی در محیط واقعیت مجازی به در بهتر از diagnosticity محصولات کمک می کند.
به طور کلی می توان این را بیان کرد که کاربران بیشتر تمایل به ارائه prior rating در محیط های واقعیت مجازی نسبت به وبسایت های سنتی دارند همچنین میانگین ارزش prior rating در واقعیت مجازی به رتبه دهی بعد از خرید نزدیک تر است.
مدل مفهومی Prior rating
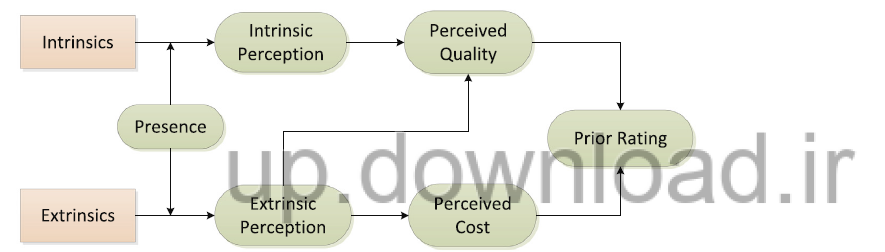
Presence: به حس کاربراندر رابطه با "بودن در آنجا" است که تا چه اندازه آنها محیط مجازی را به صورت واقعی یا در حال حاضر تجربه می کنند و به صورت موقت تجربه ی حضور فیزیکی خودشان را نادیده می گیرند.دو عامل اصلی برای این مسئله شناسایی شده به نام های زنده بودن و تعامل. زنده بودن به غنای محیط تعاملی باز می گردد که از طریق آن چه اطلاعاتی را می توان ارائه کرد. که داراری دو عنصر مهم است. وسعت حسی اشاره به تعداد ابعاد حسی به طور همزمان ارائه شده دارد.عمق حسی اشاره به تفکیک پذیری در هر کانال ادراکی دارد. تعامل، این را بیان می کنند که کاربر تا چه اندازه می تواند در اصلاح شکل و محیط واسطه در زمان واقعی شرکت کند.
intrinsic attributes: ویژگی های ذاتی می تواند در میان محصولات مختلف متفاوت باشد. در اینجا ویژگی های ذاتی به سه نوع تقسیم شده اند. 1- ظاهر، اشاره به صفاتی که به نمایندگی سطحی محصولات مربوط می شوند دارد مانند الگوها، شکل، اندازه و غیره.2- ماده، به ویژگی هایی که محصول از آن ساخته اشاره دارد مانند خواص پارچه، وزن و غیره. 3-قابلیت ها، به ویژگی هایی که محصول برای ما سودمندی دارد اشاره می کند یا این که بر روی محصول چه عملی می توان انجام داد و یا این که اعمالی که آن محصول برای ما انجام می دهد.
Extrinsic attributes: بر خلاف ویژگی های ذاتی، این دسته از ویژگی ها(مانند قیمت، نوع محصول و غیره) هیچ تاثیر مستقیمی بر کیفیت درک شده از محصول ندارند.آنها بیشتر زمانی که اطلاعات در رابطه با ویژگی های ذاتی ناقص است به عنوان نشانه برای پی بردن به کیفیت محصول استفاده می شوند.
نتیجه گیری
به سمت طراحی سیستم های پیشنهاد دهنده برای تجارت الکترونیک و بر اساس واقعیت مجازی حرکت می کنیم. در اینجا منبع اطلاعات جدیدی به نام prior rating معرفی شد که با اعمال نفوذ تاثیرتعاملات بین کاربر و محصولات مجازی که در محیط واسطه نشان داده شده است، prior rating نظر کاربر را در رابطه با محصول دریافت می کند که از تجربه ی محصول مجازی نشات می گیرد. در اینجا مدلی مفهومی از prior rating ارائه شد. مطالعه کاربر در دو محیط مختلف بررسی شد یعنی وبسایت و فروشگاه مجازی که کاربر با محصول در تعامل بود.برخلاف محیط سنتی، کاربران در فروشگاه مجازی احساس راحتی بیشتری دارند و همین طور انگیزه بیشتری برای امتیازدهی به محصول دارند. این موضوع سبب می شود که به prior rating اعتماد بیشتری بتوان کرد زیرا به رتبه ی بعد از خرید نزدیک تر است. به این موضوع پرداخته شده است که تکرار تاثیر مثبتی بر برداشت، از تجربه ی برخی ویژگی های محصولات مرتبط دارد.برای بررسی کیفیت محصول، کاربران بیشتر بر صفات بیرونی محیط های سنتی تکیه دارند. در حالی که کاربران در واقعیت مجازی بیشتر بر ویژگی های ذاتی تکیه دارند.Prior rating می تواند رتبه دهی بعد از خرید را کامل کند و به بهبود مشکلات data spasity و cold start کمک کند. این مسئله وجود دارد که کاربران بیشتر به مرور کردن محصولات می پردازند تا خرید کردن .هر چقدر که میزان حضور بالاتر باشد می توان اعتماد بیشتری به prior rating کرد و برای این موضوع باید برای طراحی فروشگاه های مجازی با تاکید بر افزایش غنای رسانه ها یا اثربخشی تعاملات کاربران تاکید شود.
مراجع
1- Lalita Sharma, Anju Gera, A Survey of Recommendation System: Research Challenges,International Journal of Engineering Trends and Technology,2013
2- Guibing Guo , Jie Zhang , Daniel Thalmann , Neil Yorke-Smith,Leveraging prior ratings for recommender systems in e-commerce, Electronic Commerce Research and Applications 13 (2014) 440–455
3-Guo, G., Zhang, J., Thalmann, D., and Yorke-Smith, N. Prior ratings: a new information source for recommender systems in e-commerce. In Proceedings of the 7th ACM Conference on Recommender Systems 2013.